
Dataset Preparation
Important
The functionality and interfaces of the dataset section will be managed by the benco CLI in subsequent versions.
For now, it is temporarily necessary to manually manage the corresponding json or dataset paths in each working path to complete the deployment.
Tampering Detection Task Dataset Introduction
- Currently, tampering detection generally includes two types of tasks:
- Organized in Detection form, perform image-level binary classification on a whole image to determine whether the image is tampered with.
- Organized in Segmentation form, generate a pixel-level binary classification mask for an image to segment the tampered area.
- Therefore, generally speaking, a record in a tampering detection dataset includes the following content:
- A tampered image, image
- A corresponding binary mask of the tampered area
- A 0, 1 label representing whether the image has been tampered with.
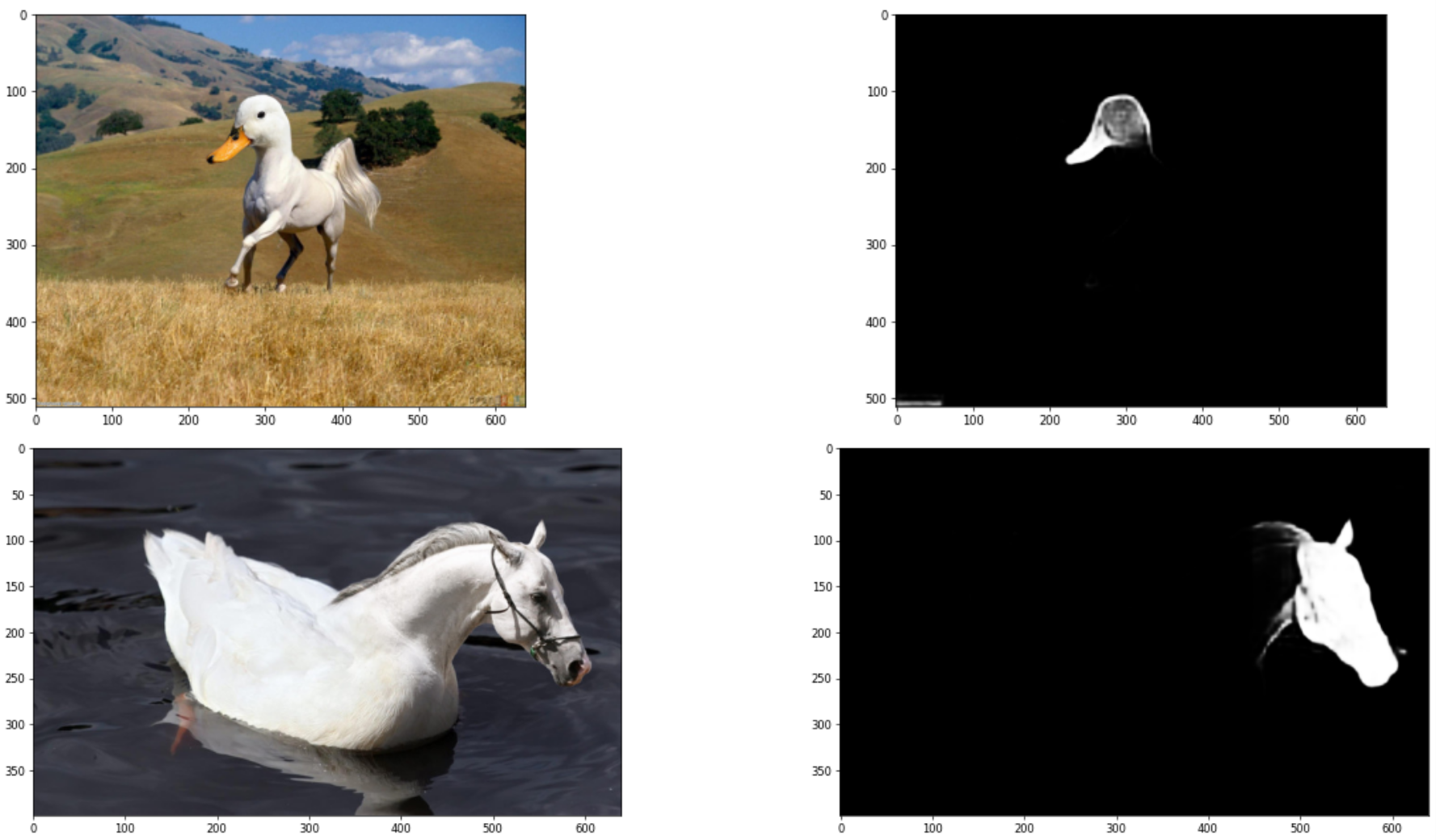
- Below are two typical pairs of tampered images and their corresponding masks:
- Many papers only use "datasets that only contain tampered images". Recently, some papers have tried to introduce real images for training. Although this can reduce the false positive rate, it will cause a slight decrease in overall metrics (the model will tend not to predict, missing some positive points).
Dataset Format and Features
- IMDL-BenCo internally implements three different dataset formats, corresponding to different dataset organization methods. Various tampering datasets can be organized into these formats for the framework to read.
- The preset dataset formats of IMDL-BenCo include two basic
JsonDatasetandManiDataset, used for reading individual datasets. There is also aBalanceDataset, which manages multiple datasets according to a special sampling strategy. Organizing the dataset in any of these three ways allows it to be read by IMDL-BenCo. Their specific introductions are as follows:ManiDataset, automatically reads all images in two folders (named./Tpand./Gt) under a path, serving as the image to be tested and the corresponding mask. Suitable for lightweight development and occasions where real images do not need to be introduced.JsonDataset, indexes the paths of required data through a Json file, suitable for occasions where real images need to be introduced.BalancedDataset, this dataset manages a dictionary that stores multipleManiDatasetorJsonDatasetobjects, and randomly samples n images from all the sub-datasets it contains in each Epoch (default only samples 1800 images). Therefore, the actual number of images participating in training in one Epoch is the number of datasets × n, but when the dataset is large enough, the richness of images over multiple Epochs can still be high. Moreover, it avoids the model trained after being too "overfitted" to large datasets.BalancedDatasetis mainly designed for the protocols of CAT-Net and TruFor. If you are not reproducing the protocol for this agreement, you do not need to pay attention.
The above datasets can be used for direct training or testing. In addition, to improve efficiency in testing, multiple different datasets can be tested in sequence in one round of scripts, so an additional Json format is defined for inputting a large number of datasets, with an example at the end of this section.
Specific Definition Format
ManiDataset, pass in a folder path, the folder contains two sub-foldersTpandGt, benco automatically reads images fromTp, reads corresponding masks fromGt, and automatically pairs all image files in the two folders according to dictionary order to obtain a complete dataset. You can refer to the IML-ViT sample folder.JsonDataset, pass in a JSON file path, organize images and corresponding masks with the following JSON format:[ [ "/Dataset/CASIAv2/Tp/Tp_D_NRN_S_N_arc00013_sec00045_11700.jpg", "/Dataset/CASIAv2/Gt/Tp_D_NRN_S_N_arc00013_sec00045_11700_gt.png" ], ...... [ "/Dataset/CASIAv2/Au/Au_nat_30198.jpg", "Negative" ], ...... ]Where "Negative" indicates a completely black mask, i.e., a completely real image, so there is no need to input the path.
BalancedDataset, pass in a JSON file path, used to organize and generate multiple sub-datasets, and sample from these sub-datasets when used. Specifically for organizing the protocols used in CAT-Net and TruFor.- Specific protocol definition: Protocol-CAT uses 9 large datasets for training, but only randomly samples 1800 images from each dataset to form a 16200-image dataset for training in each Epoch.
- Json organization form:
[ [ "ManiDataset", "/mnt/data0/public_datasets/IML/CASIA2.0" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/FantasticReality_v1/FantasticReality.json" ], [ "ManiDataset", "/mnt/data0/public_datasets/IML/IMD_20_1024" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/compRAISE/compRAISE_1024_list.json" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/tampCOCO/sp_COCO_list.json" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/tampCOCO/cm_COCO_list.json" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/tampCOCO/bcm_COCO_list.json" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/tampCOCO/bcmc_COCO_list.json" ] ]A two-dimensional array, each row represents a dataset, the first column represents the string of the dataset Class type used (read the corresponding dataset according to the organization method of
ManiDatasetorJsonDataset), and the second column is the path of the dataset that needs to be read for this type.
Organize the datasets needed according to the requirements, and then you can start considering reproducing the model or implementing your own model.
In addition to the format to be noted, to improve the speed of training and testing, it is also necessary to perform necessary preprocessing on the images.
Preprocessing for High-Resolution Images
Some datasets have very high resolutions, such as the NIST16 and compRAISE datasets in the CAT-Protocol, which contain 4000x4000 images. These datasets, if directly read during training, will bring a very high I/O burden. Especially when used as training datasets.
So we particularly recommend resizing the images to a smaller size in advance when using these datasets, such as reducing to a long side equal to 1024 while maintaining the aspect ratio. Otherwise, the training speed may be greatly slowed down, please refer to IMDL-BenCo issue #40.
We provide a Resize code based on a thread pool here, which can efficiently convert all images in a path to the desired resolution through multi-threading:
import os
from PIL import Image
from concurrent.futures import ThreadPoolExecutor
def process_image(filename, directory, output_directory, target_size):
try:
with Image.open(os.path.join(directory, filename)) as img:
width, height = img.size
print(f'Processing Image: {filename} | Resolution: {width}x{height}')
# Determine the scaling ratio with the long side as 1024
if max(width, height) > target_size:
if width > height:
new_width = target_size
new_height = int((target_size / width) * height)
else:
new_height = target_size
new_width = int((target_size / height) * width)
# Resize the image
img_resized = img.resize((new_width, new_height), Image.ANTIALIAS)
# Save the image to the specified folder
output_path = os.path.join(output_directory, filename)
img_resized.save(output_path)
print(f'Resized and saved {filename} to {output_directory} with resolution {new_width}x{new_height}')
else:
# If the image does not need to be adjusted, directly copy it to the target folder
img.save(os.path.join(output_directory, filename))
print(f'Image {filename} already meets the target size and was saved without resizing.')
return 1 # Return the count of successful processing
except Exception as e:
print(f"Cannot process {filename}: {e}")
return 0 # Return the count of failed processing
def get_image_resolutions_and_resize(directory='.', output_directory='resized_images', target_size=1024):
# Create the output folder, create if it does not exist
if not os.path.exists(output_directory):
os.makedirs(output_directory)
# Get all image files
image_files = [f for f in os.listdir(directory) if f.lower().endswith(('png', 'jpg', 'jpeg', 'bmp', 'gif', 'tiff'))]
# Use a thread pool to process images
total_processed = 0
with ThreadPoolExecutor() as executor:
futures = [executor.submit(process_image, filename, directory, output_directory, target_size) for filename in image_files]
# Wait for all threads to complete and accumulate the number of processed
for future in futures:
total_processed += future.result()
# Output the total number of images
print(f"\nTotal number of images processed: {total_processed}")
# Execute the function
get_image_resolutions_and_resize(
directory="./compRAISE",
output_directory="./compRAISE1024",
target_size=1024
)
Test Dataset JSON
Specifically, for testing, since batch testing needs to be completed on multiple datasets, a test_dataset.json is defined to accomplish this function. Because it is the testing phase, only paths representing ManiDataset or JsonDataset can be passed as test sets; different from BalancedDataset, which can only be used for training.
The Key is the field name used for Tensorboard, log output, and other Visualize features, and the Value is the specific path of the above datasets.
An example of test_datasets.json, directly pass the path of this json to the training script as the test set (introduced later):
{
"Columbia": "/mnt/data0/public_datasets/IML/Columbia.json",
"NIST16_1024": "/mnt/data0/public_datasets/IML/NIST16_1024",
"NIST16_cleaned": "/mnt/data0/public_datasets/IML/NIST16_1024_cleaning",
"coverage": "/mnt/data0/public_datasets/IML/coverage.json",
"CASIAv1": "/mnt/data0/public_datasets/IML/CASIA1.0",
"IMD20_1024": "/mnt/data0/public_datasets/IML/IMD_20_1024"
}