
数据集准备
重要
数据集部分的功能和接口会在后续版本中由benco CLI统一管理。
目前暂时需要手动在每一个工作路径下管理相应的json或数据集路径完成部署。
篡改检测任务数据集简介
- 目前篡改检测一般包含两种任务:
- 以Detection形式组织,对一张图整图进行image-level的二分类,判断这张图是否是篡改的。
- 以Segmentation形式组织,对一张图生成一个pixel-level的二分类mask,分割出篡改区域。
- 所以,一般来说,一个篡改检测数据集的一条记录包含如下内容:
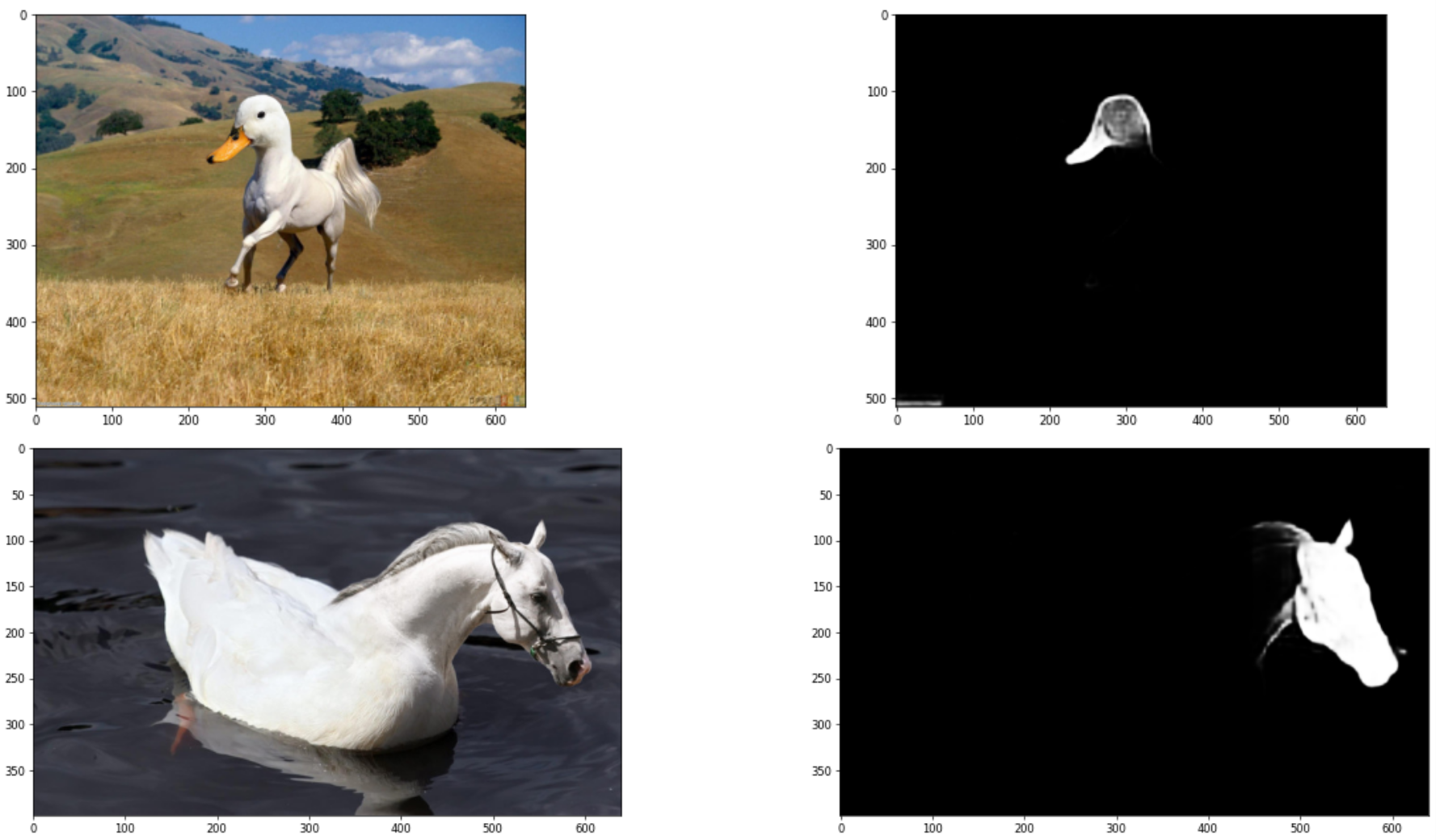
- 一张篡改图像,image
- 一张对应的篡改区域的二值mask
- 一个0,1标签,代表这张图是否被篡改。
- 以下是两对典型的篡改图像图和对应的mask:
- 很多论文只使用“仅包含篡改图像的数据集”。最近一些论文会尝试引入真图一起训练,虽然可以降低假阳性率,但是会导致总体的指标略微降低(模型会倾向于不预测,错过一些阳性点)。
数据集格式和特点
- IMDL-BenCo内部实现了3种不同的数据集格式,对应不同的数据集组织方式,可以根据需求将各种篡改数据集组织为这样的格式来让框架进行读取。
- IMDL-BenCo预设的数据集格式包含两个基础的
JsonDataset和ManiDataset,用于读取单个数据集。以及一个BalanceDataset,它按照一种特殊的采样策略同时管理多个数据集。将数据集按照这三种方式的任何一种组织好,即可由IMDL-BenCo读取。它们的具体介绍如下:ManiDataset,自动读取一个路径下的两个文件夹(需要命名为./Tp和./Gt)下的所有图片,分别作为待测图像和对应的mask。适合轻量开发,且不需要引入真实图片的场合。JsonDataset,通过一个Json文件索引到所需数据的路径,适合需要引入真实图片的场合。BalancedDataset,这种数据集管理了一个字典,存放了多个ManiDataset或JsonDataset对象,在每一个Epoch分别从它所包含的所有子数据集中随机采样n张图片(默认只采样1800张)进行,所以实际一个Epoch参与训练的图片数量=数据集数量 × n,但当数据集足够大时,多个Epoch下图片的丰富度仍然可以很高。并且,避免训练后的模型过于向大数据集“过拟合”。BalancedDataset主要针对CAT-Net 和 TruFor的协议设计,如果不针对该协议复现则不需要关注。
上述数据集可以用于直接训练或测试。此外,在测试为了提高效率,可以在一轮脚本中依次测试多个不同的数据集,所以额外定义了一种Json格式用于输入大量数据集,在本段末尾有样例。
具体定义格式
ManiDataset,传入一个文件夹路径,该文件夹包含两个子文件夹Tp和Gt,benco自动从Tp中读取图片,从Gt中读取对应mask,并自动按照字典序将两个文件夹下的所有图片文件逐一配对,得到完整数据集。可以参考IML-ViT中的样例文件夹。JsonDataset,传入一个JSON文件路径,使用如下JSON格式组织图片和对应mask:[ [ "/Dataset/CASIAv2/Tp/Tp_D_NRN_S_N_arc00013_sec00045_11700.jpg", "/Dataset/CASIAv2/Gt/Tp_D_NRN_S_N_arc00013_sec00045_11700_gt.png" ], ...... [ "/Dataset/CASIAv2/Au/Au_nat_30198.jpg", "Negative" ], ...... ]其中“Negative”表示全黑的mask,即完全真实的图片,所以也不需要输入path。
BalancedDatast,传入一个JSON文件路径,用于组织生成多个子数据集,并在使用时从这些子数据集中采样。,专门用来组织CAT-Net和TruFor中使用的协议。- 协议具体定义:Protocol-CAT使用到了9个大数据集进行训练,但是每一个Epoch只从每个数据集中随机采样1800张图组成一个16200张图的数据集完成训练。
- Json组织形式:
[ [ "ManiDataset", "/mnt/data0/public_datasets/IML/CASIA2.0" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/FantasticReality_v1/FantasticReality.json" ], [ "ManiDataset", "/mnt/data0/public_datasets/IML/IMD_20_1024" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/compRAISE/compRAISE_1024_list.json" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/tampCOCO/sp_COCO_list.json" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/tampCOCO/cm_COCO_list.json" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/tampCOCO/bcm_COCO_list.json" ], [ "JsonDataset", "/mnt/data0/public_datasets/IML/tampCOCO/bcmc_COCO_list.json" ] ]二维数组,每一行代表一个数据集,第一列代表使用到的数据集Class类型的字符串(按照
ManiDataset或JsonDataset的组织方式读取对应数据集),第二列是该类型需要读取数据集的路径。
将需要用的数据集按照需求,组织好后,即可开始考虑复现模型或实现自己的模型。
除了格式需要注意,为了提高训练测试速度,还需要对图片进行必要的预处理。
对于高分辨率图片的预处理
有一些数据集本身有很高的分辨率,比如NIST16和CAT-Protocol中的compRAISE数据集都含有4000x4000的图片。这些数据集如果在训练时直接读取会带来极高的I/O负担。尤其是作为训练数据集时。
所以我们尤其建议使用这些数据集时提前将图片resize到小尺寸,比如保持长宽比的情况下缩小到长边等于1024。否则训练速度可能会被极大拖慢,请参考IMDL-BenCo issue #40。
我们这里提供一个基于线程池的Resize代码,可以高效地通过多线程将一个路径下的所有图片转换为期望的分辨率:
import os
from PIL import Image
from concurrent.futures import ThreadPoolExecutor
def process_image(filename, directory, output_directory, target_size):
try:
with Image.open(os.path.join(directory, filename)) as img:
width, height = img.size
print(f'Processing Image: {filename} | Resolution: {width}x{height}')
# 确定长边为1024的缩放比例
if max(width, height) > target_size:
if width > height:
new_width = target_size
new_height = int((target_size / width) * height)
else:
new_height = target_size
new_width = int((target_size / height) * width)
# 调整图片尺寸
img_resized = img.resize((new_width, new_height), Image.ANTIALIAS)
# 保存图片到指定文件夹
output_path = os.path.join(output_directory, filename)
img_resized.save(output_path)
print(f'Resized and saved {filename} to {output_directory} with resolution {new_width}x{new_height}')
else:
# 如果图片不需要调整,直接复制到目标文件夹
img.save(os.path.join(output_directory, filename))
print(f'Image {filename} already meets the target size and was saved without resizing.')
return 1 # 返回处理成功的计数
except Exception as e:
print(f"Cannot process {filename}: {e}")
return 0 # 返回处理失败的计数
def get_image_resolutions_and_resize(directory='.', output_directory='resized_images', target_size=1024):
# 创建输出文件夹,如果不存在则创建
if not os.path.exists(output_directory):
os.makedirs(output_directory)
# 获取所有图片文件
image_files = [f for f in os.listdir(directory) if f.lower().endswith(('png', 'jpg', 'jpeg', 'bmp', 'gif', 'tiff'))]
# 使用线程池处理图片
total_processed = 0
with ThreadPoolExecutor() as executor:
futures = [executor.submit(process_image, filename, directory, output_directory, target_size) for filename in image_files]
# 等待所有线程完成并累加处理的数量
for future in futures:
total_processed += future.result()
# 输出总图片数量
print(f"\nTotal number of images processed: {total_processed}")
# 执行函数
get_image_resolutions_and_resize(
directory="./compRAISE",
output_directory="./compRAISE1024",
target_size=1024
)
测试用数据集JSON
特别的,对于测试时,因为要分别在多个数据集上完成批量测试,所以专门定义一个test_dataset.json来完成这个功能。因为是测试阶段,所以只能传入代表ManiDataset或JsonDataset的路径作为测试集;区别于BalancedDataset只能用于训练。
Key为Tensorboard,日志输出等等Visualize功能时使用的字段名,Value为上述数据集的具体路径。
一个test_datasets.json样例,直接传该json的路径给训练脚本作为测试集即可(后文会介绍):
{
"Columbia": "/mnt/data0/public_datasets/IML/Columbia.json",
"NIST16_1024": "/mnt/data0/public_datasets/IML/NIST16_1024",
"NIST16_cleaned": "/mnt/data0/public_datasets/IML/NIST16_1024_cleaning",
"coverage": "/mnt/data0/public_datasets/IML/coverage.json",
"CASIAv1": "/mnt/data0/public_datasets/IML/CASIA1.0",
"IMD20_1024": "/mnt/data0/public_datasets/IML/IMD_20_1024"
}