
案例三:使用benco init实现你自己的模型
我们认为学习最快的方式就是“Learn by Doing”(边做边学),所以通过几个案例来帮助使用者快速上手。
总的来说IMDL-BenCo通过类似git、conda这样的命令行调用方式帮助你快速完成图像篡改检测科研项目的开发。如果你学过vue等前端技术,那按照vue-cli来理解IMDLBenCo的设计范式会非常轻松。
无论如何,请先参考安装完成IMDL-BenCo的安装。
本章动机
为了确保你能灵活创建自己的模型,本章会帮你理解IMDL-BenCo的设计模式和接口范式。我们按照使用流程逐步深入介绍每个部分。
介绍所有设计模式
生成默认脚本
在一个干净的工作路径下,执行如下命令行指令即可生成创建自己模型并测试所需的全部脚本,作为默认指令,省略base执行的也是同样的命令。
benco init base
benco init
正常执行后会看到在当前路径下生成了如下文件,它们的用途如注释所示:
.
├── balanced_dataset.json # 存放按照Protocol-CAT组织的数据集路径
├── mymodel.py # 核心的模型实现
├── README-IMDLBenCo.md # 一个简单的readme
├── test_datasets.json # 存放测试用的数据集路径
├── test_mymodel.sh # 传参运行测试的shell脚本
├── test.py # 测试脚本的实际Python代码
├── test_robust_mymodel.sh # 传参运行鲁棒性测试的shell脚本
├── test_robust.py # 鲁棒性测试的实际Python代码
├── train_mymodel.sh # 传参运行的训练shell脚本
└── train.py # 训练脚本的实际Python代码
特别注意
如果已经生成过脚本,并且做出一定修改后,请一定小心二次调用benco init,IMDLBenCo会在询问后逐一覆盖文件,如果误操作可能导致丢失你已有的修改,务必小心。推荐使用git版本管理来避免该操作导致丢失已有代码。
模型文件设计范式
IMDLBenCo需要按照一定格式组织模型文件,以保证入口可以和DataLoader、出口可以和后续的Evaluator和Visualize tools对齐。
执行benco init后默认以最简单的单层卷积生成一个模型在mymodel.py中,你可以先通过Github中的mymodel.py链接快速查看它的内容。
from IMDLBenCo.registry import MODELS
import torch.nn as nn
import torch
@MODELS.register_module()
class MyModel(nn.Module):
def __init__(self, MyModel_Customized_param:int, pre_trained_weights:str) -> None:
"""
The parameters of the `__init__` function will be automatically converted into the parameters expected by the argparser in the training and testing scripts by the framework according to their annotated types and variable names.
In other words, you can directly pass in parameters with the same names and types from the `run.sh` script to initialize the model.
"""
super().__init__()
# Useless, just an example
self.MyModel_Customized_param = MyModel_Customized_param
self.pre_trained_weights = pre_trained_weights
# A single layer conv2d
self.demo_layer = nn.Conv2d(
in_channels=3,
out_channels=1,
kernel_size=3,
stride=1,
padding=1,
)
# A simple loss
self.loss_func_a = nn.BCEWithLogitsLoss()
def forward(self, image, mask, label, *args, **kwargs):
# simple forwarding
pred_mask = self.demo_layer(image)
# simple loss
loss_a = self.loss_func_a(pred_mask, mask)
loss_b = torch.abs(torch.mean(pred_mask - mask))
combined_loss = loss_a + loss_b
pred_label = torch.mean(pred_mask)
inverse_mask = 1 - mask
# ----------Output interface--------------------------------------
output_dict = {
# loss for backward
"backward_loss": combined_loss,
# predicted mask, will calculate for metrics automatically
"pred_mask": pred_mask,
# predicted binaray label, will calculate for metrics automatically
"pred_label": pred_label,
# ----values below is for visualization----
# automatically visualize with the key-value pairs
"visual_loss": {
# keys here can be customized by yourself.
"predict_loss": combined_loss,
'loss_a' : loss_a,
"I am loss_b :)": loss_b,
},
"visual_image": {
# keys here can be customized by yourself.
# Various intermediate masks, heatmaps, and feature maps can be appropriately converted into RGB or single-channel images for visualization here.
"pred_mask": pred_mask,
"reverse_mask" : inverse_mask,
}
# -------------------------------------------------------------
}
return output_dict
if __name__ == "__main__":
print(MODELS)
按照代码从前到后的顺序介绍,IMDLBenCo的model文件需要满足以下设计才能正常运行:
- 第5行:
@MODELS.register_module()- 基于注册机制注册该模型到IMDLBenCo的全局注册器中,便于其他脚本通过字符串快速调用该类。
- 如果对注册机制不熟悉,一句话解释就是:自动维护了一个从字符串到对应类的字典映射,便于“自由地”传递参数。
- 实际使用时,通过向启动训练的shell脚本的
--model函数传入注册过的“类名同名字符串”即可使得框架加载对应的自定义or框架内已有模型。具体请参考此链接。
- 第29行、第37行:损失函数必须定义在
__init__()或者forward()函数中 - 第31行:定义forward函数时
def forward(self, image, mask, label, *args, **kwargs):- 必须要带Python函数解包所需的
*args, **kwargs,以接收未使用的参数。 - 形参变量名必须与
abstract_dataset.py中返回的字典data_dict包含的字段名完全一致。默认字段如下表所示:Key名 含义 类型 image 输入的原始图片 Tensor(B,3,H,W) mask 预测目标的掩码 Tensor(B,1,H,W) edge_mask 根据mask进行腐蚀(erosion)与膨胀(dilation)后获得的仅有边界为白色的mask,以供各种需要边界损失函数的模型使用。为了减轻计算开销,必须在训练 shell中传入--edge_mask_width 7这样的参数后,对应的dataloader才会返回这个键值对供模型的forward()函数取用,参考IML-ViT的shell和模型forward函数函数。
如果不需要边界mask来计算后续损失,则既不需要在shell中传入,也不需要在模型的forward()函数形参中准备名为edge_mask的形参,参考ObjectFormer的shell和模型forward函数。Tensor(B,1,H,W) lable Image-level预测的零一标签 Tensor(B,1) shape 经过padding或resize后,传入模型训练的图片的形状 Tensor(B,2), 两个维度各一个值,分别代表H和W original_shape 最开始读取输入的图片的形状 Tensor(B,2), 两个维度各一个值,分别代表H和W name 图片的路径和文件名 str shape_mask 在padding的情况下,仅计算该mask内为1的全部像素作为最终指标,1默认为和原图一样大的方形区域 Tensor(B,1,H,W) - 对于不同的任务,可以按需取用这些字段输入到模型中使用。
- 此外,对于CAT-Net需要的Jpeg相关的图片素材,我们设计了后处理函数
post_func来根据已有的字段,生成更多需要的内容,此时也需要保证对应的forward函数的字段对齐。有类似需求的自定义模型也可以使用这个范式来在dataloader引入其他模态的信息。 以下是CAT-Net的案例:cat_net_post_function的Github链接,可以看到包含额外的DCT_coef和q_tables两个字段为模型输入额外的模态cat_net_model的Github链接,forward函数的形参列表需要有相应字段接收上述额外输入的信息。
- 必须要带Python函数解包所需的
- 第36行到第38行:所有的损失函数必须在
forward函数中完成计算 - 第45行到第70行:输出结果的字典。非常重要!,字典各字段的功能介绍如下:
Key 含义 类型 backward_loss 直接用于反向传播的损失函数 Tensor(1) pred_mask 预测的mask,会直接用于后续指标计算 Tensor(B,1,H,W) pred_label 预测的零一标签,会直接用于后续指标计算 Tensor(B,1) visual_loss 传入需要可视化的标量。可以命名任意数量、任意名称的key并传入相应标量,后续会自动根据Key名进行可视化 Dict() visual_imagwe 传入需要可视化的图片,特征图,各种mask。可以命名任意数量,任意名称的key并传入相应Tensor,后续会自动根据Key名进行可视化 Dict() - 务必按照此格式组织,才能正常融入后续指标运算、可视化等流程。
从头到尾的保姆级教程
我们以ConvNeXt网络为模型,CASIAv2作为训练集,CASIAv1作为测试集为例,从头到尾带您体验使用IMDL-BenCo设计,训练,测试一个您自己的新模型的流程。
下载数据集
本仓库提供了目前主流篡改检测数据集的索引目录,简介,以及勘误。请参考篡改检测数据集索引章节。
提示
目前很多篡改检测数据集都是纯手工标注收集,导致存在很多错误,所以必要的勘误是必须的。常见错误包括:
- image和mask分辨率不一致;
- 有多余图片没有对应mask;
- image和mask有显然的错位标注;
更多勘误相关信息可以参考这个IML-Dataset-Corrections仓库。
- CASIAv2下载链接:
- 请参考Sunnyhaze的仓库的
Fixed groundtruth downloading章节下载完整数据集。
- 请参考Sunnyhaze的仓库的
- CASIAv1下载链接:
- 请从namtpham的仓库Readme中的网盘链接下载原始数据集图片。
- 请clone该仓库以下载图片对应的mask
git clone https://github.com/namtpham/casia1groundtruth
组织数据集到IMDL-BenCo可以读取的格式
具体格式要求请参考数据集准备章节。
- 下载好的CASIAv2数据集已经按照
ManiDataset的格式组织了,解压后即可。 - 下载好的CASIAv1数据集还需要进一步处理。我们这里分别提供
JsonDataset和ManiDataset两种方式。
首先,对于该仓库提供的原始数据集CASIA 1.0 dataset解压后可以看到文件如下:
.
├── Au.zip
├── Authentic_list.txt
├── Modified Tp.zip
├── Modified_CopyMove_list.txt
├── Modified_Splicing_list.txt
├── Original Tp.zip
├── Original_CopyMove_list.txt
└── Original_Splicing_list.txt
因为最早CASIA官方有一些文件名谬误,该仓库对于这些命名错误进行了修改。实际上我们只需要解压修改后的Modified Tp.zip即可,得到:
└── Tp
├── CM
└── Sp
其中CM下存放着Copy-move对应的篡改图像;而SP下存放着Splicing对应的篡改图像。理论上一共有921张图片。
重要!
根据勘误仓库,这里存在一张多余的图片没有对应的mask,即:CASIA1.0/Modified Tp/Tp/Sp/Sp_D_NRN_A_cha0011_sec0011_0542.jpg我们建议将这张图从这个数据集去除掉再进行后续处理。
另外,对于存放对应mask的CASIA 1.0 groundtruth解压后得到:
.
└── CASIA 1.0 groundtruth
├── CM
├── CopyMove_groundtruth_list.txt
├── FileNameCorrection.xlsx
├── Sp
└── Splicing_groundtruth_list.txt
同理,CM下存放着Copy-move对应的mask;而SP下存放着Splicing对应的mask。理论上应该有920张图片。所以为了保证image和mask能一一对应,请务必去除掉篡改图像中上述多余的一张。
接下来我们展示通过两种方式组织CASIAv1为IMDL-BenCo可以读取的数据集。
以JsonDataset为例组织数据集
通过在设置好的路径下执行如下Python脚本即可生成IMDL-BenCo可以读取的JSON文件:
import os
import json
def collect_image_paths(root_dir):
"""收集目录下所有图片文件的相对路径和绝对路径"""
image_exts = {'.jpg', '.jpeg', '.png', '.bmp', '.tif', '.tiff', '.webp'}
image_paths = []
pwd = os.getcwd()
for dirpath, _, filenames in os.walk(root_dir):
for filename in filenames:
file_ext = os.path.splitext(filename)[1].lower()
if file_ext in image_exts:
abs_path = os.path.normpath(os.path.join(dirpath, filename))
image_paths.append(os.path.join(pwd, abs_path))
return image_paths
def generate_pairs(image_root, mask_root, output_json):
# 收集图片路径
image_dict = collect_image_paths(image_root)
print("发现image数量:", len(image_dict))
mask_dict = collect_image_paths(mask_root)
print("发现的mask数量:", len(mask_dict))
assert len(image_dict) == len(mask_dict), "图片数量为{}和掩码数量{}不匹配!".format(len(image_dict), len(mask_dict))
# 生成配对列表
pairs = [
list(pairs)
for pairs in zip(sorted(image_dict), sorted(mask_dict))
]
print(pairs)
# 保存为JSON文件
with open(output_json, 'w') as f:
json.dump(pairs, f, indent=2)
print(f"成功生成 {len(pairs)} 对路径,结果已保存至 {output_json}")
return pairs
if __name__ == "__main__":
# 配置路径(根据实际情况修改)
IMAGE_ROOT = "Tp"
MASK_ROOT = "CASIA 1.0 groundtruth"
OUTPUT_JSON = "CASIAv1.json"
# 执行生成
result_pairs = generate_pairs(IMAGE_ROOT, MASK_ROOT, OUTPUT_JSON)
# 打印后5对示例以验证是否真的对齐了
print("\n后五对示例配对:")
for pair in result_pairs[-5:]:
print(f"Image: {pair[0]}")
print(f"Mask: {pair[1]}\n")
以我为例,生成了这样的json文件:
[
[
"/mnt/data0/xiaochen/workspace/IMDLBenCo_pure/guide/Tp/CM/Sp_S_CND_A_pla0016_pla0016_0196.jpg",
"/mnt/data0/xiaochen/workspace/IMDLBenCo_pure/guide/CASIA 1.0 groundtruth/CM/Sp_S_CND_A_pla0016_pla0016_0196_gt.png"
],
......
]
后续通过将这个json文件的绝对路径作为测试集参数写入shell即可,比如:
/mnt/data0/xiaochen/workspace/IMDLBenCo_pure/guide/CASIAv1.json
特别的,如果你后续自己构建的数据集有真图,则自行写脚本构建JSON的时候,需要向真图的mask的路径写入Negative这个字符串。这样Benco会将这张图看做真图,对应纯黑的mask。比如加入上面这张图想看做真图使用的话,json应该这样组织:
[
[
"/mnt/data0/xiaochen/workspace/IMDLBenCo_pure/guide/Tp/CM/Sp_S_CND_A_pla0016_pla0016_0196.jpg",
"Negative"
],
......
]
以ManiDataset为例组织数据集
十分简单,找一个干净的存放数据集的路径创建一个名为CASIAv1的文件夹,然后分别按照如下名字新建两个子文件夹:
└── CASIAv1
├── Tp
└── Gt
然后将920张篡改图像拷贝到Tp路径下,将920张mask拷贝到Gt路径下即可。后续通过将这个文件夹的路径作为测试集参数写入shell即可,比如:
/mnt/data0/xiaochen/workspace/IMDLBenCo_pure/guide/CASIAv1
在benco init下调整设计自己的模型。
首先,我们需要执行benco init生成所需的所有文件和脚本。在本章前半部分已经对生成的文件做了简要介绍。
自定义自己的模型,要修改mymodel.py,我们先给出修改后的代码,然后对重要的部分加以介绍。
from IMDLBenCo.registry import MODELS
import torch.nn as nn
import torch
import torch.nn.functional as F
import timm
class ConvNeXtDecoder(nn.Module):
"""适配ConvNeXt的特征解码器"""
def __init__(self, encoder_channels=[96, 192, 384, 768], decoder_channels=[256, 128, 64, 32]):
super().__init__()
# 使用转置卷积逐步上采样
self.decoder = nn.Sequential(
nn.ConvTranspose2d(encoder_channels[-1], decoder_channels[0], kernel_size=4, stride=4), # 16x16 -> 64x64
nn.GELU(),
nn.ConvTranspose2d(decoder_channels[0], decoder_channels[1], kernel_size=4, stride=4), # 64x64 -> 256x256
nn.GELU(),
nn.Conv2d(decoder_channels[1], decoder_channels[2], kernel_size=3, padding=1),
nn.GELU(),
nn.Conv2d(decoder_channels[2], decoder_channels[3], kernel_size=3, padding=1),
nn.GELU(),
nn.Conv2d(decoder_channels[3], 1, kernel_size=1)
)
def forward(self, x):
return self.decoder(x)
@MODELS.register_module()
class MyConvNeXt(nn.Module):
def __init__(self) -> None:
super().__init__()
# 初始化ConvNeXt-Tiny骨干网络
self.backbone = timm.create_model(
"convnext_tiny",
pretrained=True,
features_only=True,
out_indices=[3], # 取最后一个特征图 (1/32下采样)
)
# 分割解码器
self.seg_decoder = ConvNeXtDecoder()
# 分类头
self.cls_head = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(768, 1) # ConvNeXt-Tiny最后通道数是768
)
# 损失函数
self.seg_loss = nn.BCEWithLogitsLoss()
self.cls_loss = nn.BCEWithLogitsLoss()
def forward(self, image, mask, label, *args, **kwargs):
# 特征提取
features = self.backbone(image)[0] # 获取最后一个特征图 [B, 768, H/32, W/32]
# 分割预测
seg_pred = self.seg_decoder(features)
seg_pred = F.interpolate(seg_pred, size=mask.shape[2:], mode='bilinear', align_corners=False)
# 分类预测
cls_pred = self.cls_head(features).squeeze(-1)
# 计算损失
seg_loss = self.seg_loss(seg_pred, mask)
cls_loss = self.cls_loss(cls_pred, label.float())
combined_loss = seg_loss + cls_loss
# 构建输出字典
output_dict = {
"backward_loss": combined_loss,
"pred_mask": torch.sigmoid(seg_pred),
"pred_label": torch.sigmoid(cls_pred),
"visual_loss": {
"total_loss": combined_loss,
"seg_loss": seg_loss,
"cls_loss": cls_loss
},
"visual_image": {
"pred_mask": seg_pred,
}
}
return output_dict
if __name__ == "__main__":
# 测试代码
model = MyConvNeXt()
x = torch.randn(2, 3, 512, 512)
mask = torch.randn(2, 1, 512, 512)
label = torch.randint(0, 2, (2,)).float() # 注意标签维度调整为[batch_size]
output = model(x, mask, label)
print(output["pred_mask"].shape) # torch.Size([2, 1, 512, 512])
print(output["pred_label"].shape) # torch.Size([2])
首先我们重命名了模型的类名为class MyConvNeXt(nn.Module),只有完整模型的入口需要添加@MODELS.register_module()装饰器完成全局注册。前面的子模块class ConvNeXtDecoder(nn.Module):因为不需要被IMDL-BenCo直接调用,所以无需注册,也无需保持特别接口。
可以注意到,损失函数被定义在了__init__()函数内部,并且在forward()函数中计算了损失。
最后输出的字典,按照接口格式传回了:
backward_loss,损失函数;pred_mask,分割头的pixel-level的预测结果,是0~1的概率图,会自动用于计算pixel-level的所有指标,比如pixel-level F1;pred_label,分类头的image-level的预测结果,是0~1的概率值,会自动用于image-level的所有指标,比如image-level AUC;visual_loss,用于可视化的标量损失函数字典,按照每个Epoch数值变化给每个标量绘制折线图;visual_image,用于观察预测mask的预测tensor字典,通过tensorboard展示图片的API逐字段展示字典中所有包含的tensor。
重要
这个字典是IMDL-BenCo自动化完成计算和可视化的重要接口,请务必掌握。
修改其他脚本
首先,因为修改了mymodel.py的一些信息,首先需要修改对应文件的接口。主要包含如下地方:
train.py,test.py和test_robust.py三个文件的开头关于模型的import修改为对应的模型名- 原来是
from mymodel import MyModel, 这里修改为新的模型名from mymodel import MyConvNeXt - 当然,如果你修改了
mymodel.py的文件名也是可以的,保证对应的import一致即可。 - 如果不import,则后续训练时IMDL-BenCo会无法找到对应的模型。
- 原来是
重要的TODOs等你去修改
train.py, test.py和test_robust.py三个文件中留有很多TODO注释,是鼓励各位主动进行修改的部分。
比如想要引入Pixel-AUC等指标也需要通过手动修改该位置的TODO实现。
train_mymodel.sh这个脚本是启动训练的shell脚本,肯定需要修改。--model字段改为MyConvNeXt,模型会自动根据该字符串,从已经注册过的类匹配到对应模型。- 因为这个模型的
__init__()函数没有形参,所以这里作为样例展示的两个多余的参数--MyModel_Customized_param和--pre_trained_weights这两行直接删去即可。这个技术的文档在通过shell传入nn.module的超参数章节。 - 修改
--data_path字段为准备好的训练集路径。 - 修改
--test_data_path字段为之前准备好的测试集路径 - 修改其他的训练超参数以匹配你的设备需求,运算效率等等。 以下是一个修改好的
train_mymodel.sh的样例。
base_dir="./output_dir"
mkdir -p ${base_dir}
CUDA_VISIBLE_DEVICES=0,1 \
torchrun \
--standalone \
--nnodes=1 \
--nproc_per_node=2 \
./train.py \
--model MyConvNeXt \
--world_size 1 \
--batch_size 32 \
--test_batch_size 32 \
--num_workers 8 \
--data_path /mnt/data0/public_datasets/IML/CASIA2.0 \
--epochs 200 \
--lr 1e-4 \
--image_size 512 \
--if_resizing \
--min_lr 5e-7 \
--weight_decay 0.05 \
--edge_mask_width 7 \
--test_data_path "/mnt/data0/public_datasets/IML/CASIA1.0" \
--warmup_epochs 2 \
--output_dir ${base_dir}/ \
--log_dir ${base_dir}/ \
--accum_iter 8 \
--seed 42 \
--test_period 4 \
2> ${base_dir}/error.log 1>${base_dir}/logs.log
这里我有两张显卡,所以设置CUDA_VISIBLE_DEVICES=0,1和--nproc_per_node=2,你可以修改为你设备可以支持的数量和对应显卡编号。
开展训练
然后在该工作目录下执行如下指令即可开始训练:
sh train_mymodel.sh
发现没有输出,不要慌张,为了保存日志,所有的输出和报错均被重定向到了文件。
如果正确运行,则会在当前路径下生成一个名为output_dir_xxx或者eval_dir_xxx的文件夹,该文件夹内输出了三个日志,一个是正常的标准输出logs.log,一个是警告和报错error.log。还有一个独立的专门统计标量的log.txt
如果模型运行正常,则应该可以在logs.log末尾看到模型不断地迭代输出新的日志:
[01:51:01.408908] Epoch: [99] Total time: 0:00:47 (0.5883 s / it)
[01:51:08.313768] Averaged stats: lr: 0.000051 total_loss: 0.0379 (0.0425) seg_loss: 0.0379 (0.0425) cls_loss: 0.0000 (0.0000)
[01:51:08.319097] log_dir: ./output_dir/
[01:51:12.473905] Epoch: [100] [ 0/80] eta: 0:05:32 lr: 0.000051 total_loss: 0.0415 (0.0415) seg_loss: 0.0415 (0.0415) cls_loss: 0.0000 (0.0000) time: 4.1538 data: 2.5060 max mem: 12775
[01:51:23.468235] Epoch: [100] [20/80] eta: 0:00:43 lr: 0.000051 total_loss: 0.0383 (0.0426) seg_loss: 0.0383 (0.0426) cls_loss: 0.0000 (0.0000) time: 0.5496 data: 0.0083 max mem: 12775
[01:51:34.303514] Epoch: [100] [40/80] eta: 0:00:25 lr: 0.000051 total_loss: 0.0354 (0.0406) seg_loss: 0.0354 (0.0406) cls_loss: 0.0000 (0.0000) time: 0.5417 data: 0.0002 max mem: 12775
[01:51:45.128389] Epoch: [100] [60/80] eta: 0:00:12 lr: 0.000050 total_loss: 0.0304 (0.0401) seg_loss: 0.0304 (0.0401) cls_loss: 0.0000 (0.0000) time: 0.5412 data: 0.0002 max mem: 12775
[01:51:55.408163] Epoch: [100] [79/80] eta: 0:00:00 lr: 0.000050 total_loss: 0.0366 (0.0394) seg_loss: 0.0366 (0.0394) cls_loss: 0.0000 (0.0000) time: 0.5409 data: 0.0001 max mem: 12775
按照如上的设置,这个样例占用了两张显卡,每张卡占用4104M的显存。
这里推荐一个看显卡占用的工具gpustat,通过pip install gpustat后在命令行执行gpustat即可方便查看显卡占用以及对应用户。比如这里可以看到是我写这个教程时占用的前两张卡:
psdz Mon Mar 31 22:51:55 2025 570.124.06
[0] NVIDIA A40 | 44°C, 100 % | 18310 / 46068 MB | psdz(17442M) gdm(4M)
[1] NVIDIA A40 | 45°C, 35 % | 18310 / 46068 MB | psdz(17442M) gdm(4M)
[2] NVIDIA A40 | 65°C, 100 % | 40153 / 46068 MB | xuekang(38666M) xuekang(482M) xuekang(482M) xuekang(482M) gdm(4M)
[3] NVIDIA A40 | 76°C, 100 % | 38602 / 46068 MB | xuekang(38452M) gdm(108M) gdm(14M)
[4] NVIDIA A40 | 59°C, 100 % | 38466 / 46068 MB | xuekang(38444M) gdm(4M)
[5] NVIDIA A40 | 63°C, 100 % | 38478 / 46068 MB | xuekang(38456M) gdm(4M)
此时可以通过执行下列指令调出tensorboard来监视训练过程:
tensorboard --logdir ./
打开它给出的对应网址,如果你用的是服务器,vscode或者pycharm都会帮你把这个端口转发到你本地计算机的对应端口。按住ctrl单击对应链接即可。我这里是访问
http://localhost:6006/
在Tensorboard中,我们可以看到很多有用的指标,可以监测训练过程和模型的收敛情况。它们全部和my_model.py中模型的forward()函数返回的字典中的信息对应。
# 构建输出字典
output_dict = {
"backward_loss": combined_loss,
"pred_mask": torch.sigmoid(seg_pred),
"pred_label": torch.sigmoid(cls_pred),
"visual_loss": {
"total_loss": combined_loss,
"seg_loss": seg_loss,
"cls_loss": cls_loss
},
"visual_image": {
"pred_mask": seg_pred,
}
}
return output_dict
损失函数的可视化对应visual_loss字段对应的字典:
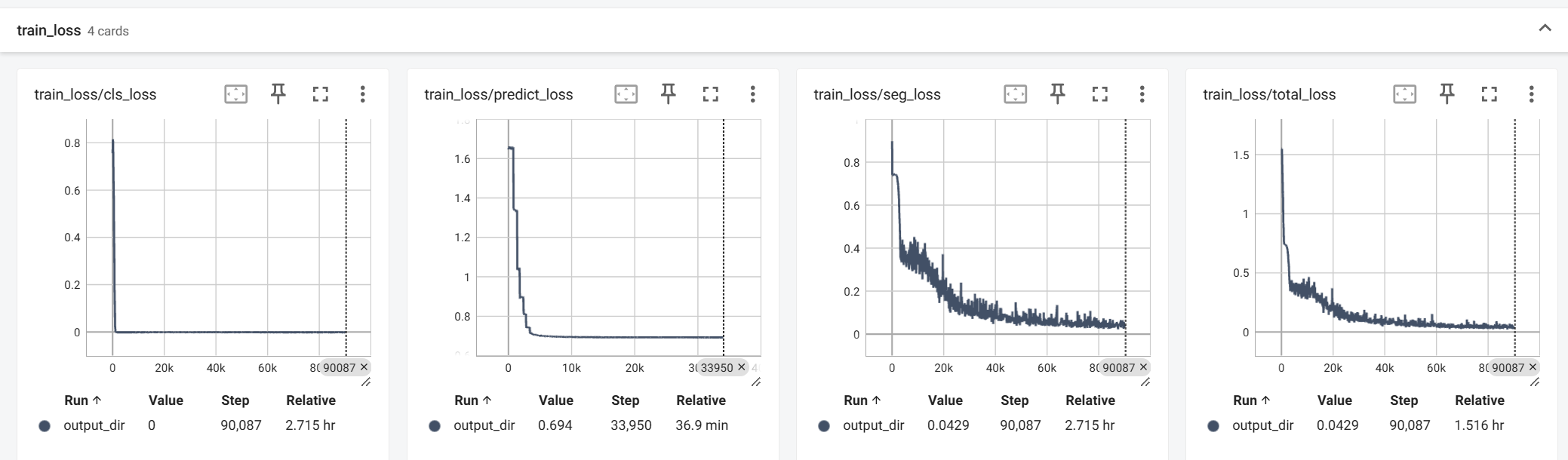
评价指标的计算来自于pred_mask和pred_label的结果和mask计算得到:
![]()
可视化的预测结果,由visual_image字段得到,且默认输入的image,mask等图像也会自动被可视化输出,用于直接观察模型当前预测不好的地方在哪,方便进一步改进模型。
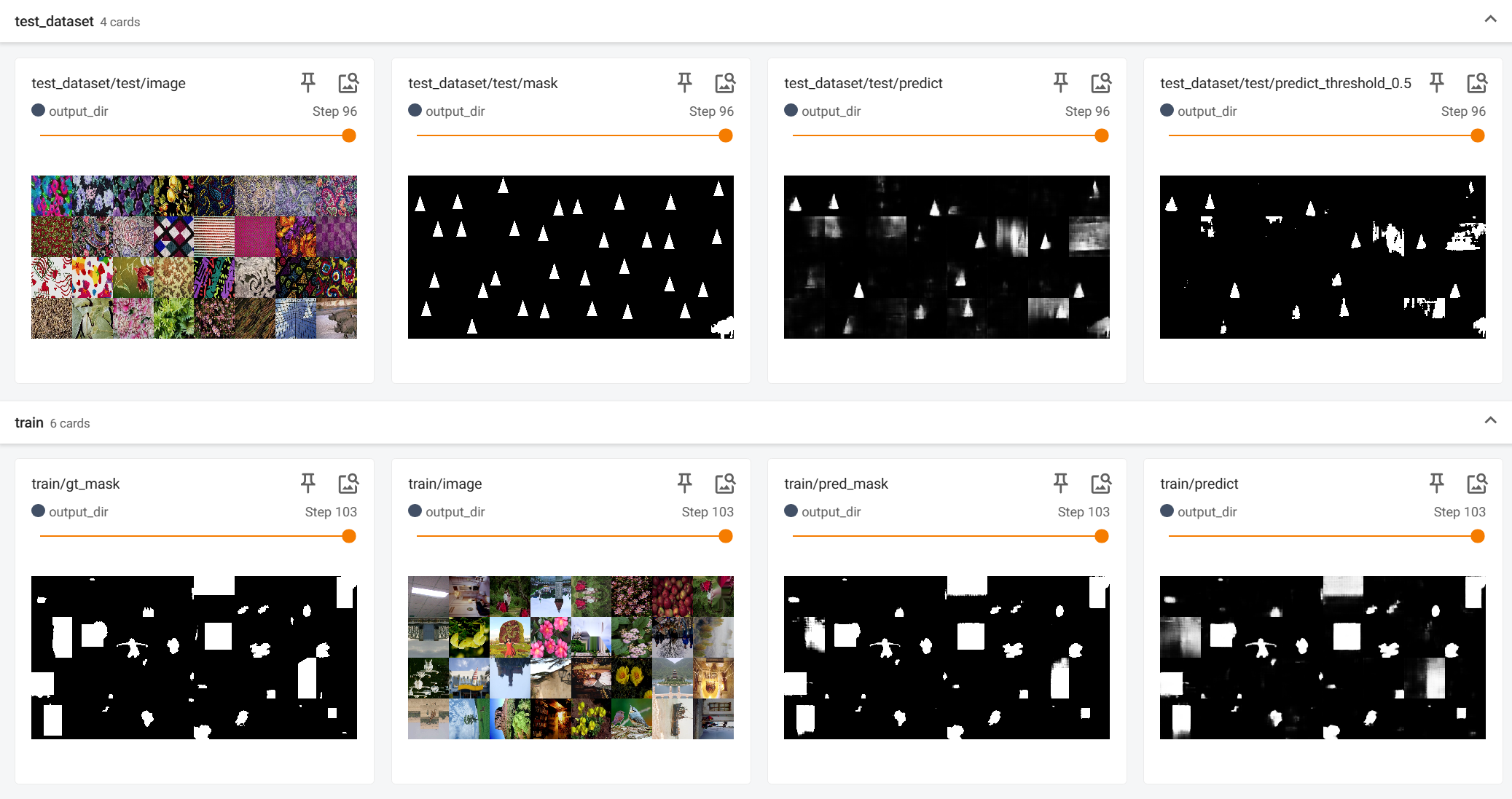
注意
教程这里应该有图片样例,如果没看到图片,请检查网络连接或开启VPN。
所有训练后得到的权重(Checkpoint)都保存在了训练train_mymodel.sh脚本开头的base_dir所对应的路径中。相应的Tensorboard的日志文件也保存在这里,以供后续取用和查阅日志。
除了Tensorboard日志,我们还提供了一个纯文本的日志log.txt留作档案,它保存的内容比较简单,只包含每一个Epoch结束后所有的标量信息。样例如下:
......
{"train_lr": 5.068414063259753e-05, "train_total_loss": 0.040027402791482446, "train_seg_loss": 0.04001608065957309, "train_cls_loss": 1.1322131909352606e-05, "test_pixel-level F1": 0.6269838496863315, "epoch": 100}
{"train_lr": 4.9894792537480576e-05, "train_total_loss": 0.03938291078949974, "train_seg_loss": 0.039372251576574625, "train_cls_loss": 1.0659212925112626e-05, "epoch": 101}
{"train_lr": 4.910553386394297e-05, "train_total_loss": 0.039195733024078264, "train_seg_loss": 0.039184275720948555, "train_cls_loss": 1.1457303129702722e-05, "epoch": 102}
{"train_lr": 4.8316563303634596e-05, "train_total_loss": 0.0385435631179897, "train_seg_loss": 0.03853294577689024, "train_cls_loss": 1.061734109946144e-05, "epoch": 103}
{"train_lr": 4.752807947567499e-05, "train_total_loss": 0.035692626619510615, "train_seg_loss": 0.03568181328162471, "train_cls_loss": 1.0813337885906548e-05, "test_pixel-level F1": 0.6672104743469334, "epoch": 104}
模型每4个Epoch测试一次,所以只有对应的epoch才会保存test_pixel-level F1。
至此,我们就解释完了所有训练过程中的输出内容。
开展测试
我们在前面的指标测试中看到在104Epoch时,模型还有上涨趋势,但为了节约时间,我们将训练停在这里,开展后续的测试。
篡改检测数据集之间的鸿沟较大,泛化性能是衡量模型性能最重要的指标,所以我们希望一次性测量所有指标。区别于前面的教程,我们要用到一次性可以涵盖多个测试集的test_datasets.json文件来帮助测试。其格式如下,我们也在benco init后的文件中提供了此文件的样例。
{
"Columbia": "/mnt/data0/public_datasets/IML/Columbia.json",
"NIST16_1024": "/mnt/data0/public_datasets/IML/NIST16_1024",
"NIST16_cleaned": "/mnt/data0/public_datasets/IML/NIST16_1024_cleaning",
"coverage": "/mnt/data0/public_datasets/IML/coverage.json",
"CASIAv1": "/mnt/data0/public_datasets/IML/CASIA1.0",
"IMD20_1024": "/mnt/data0/public_datasets/IML/IMD_20_1024"
}
这里需要您预先处理好每一个数据集,数据集索引在篡改检测数据集索引章节,格式要求在数据集准备章节。上述路径必须整理为ManiDataset或者JsonDataset的格式。,
然后我们修改test_mymodel.sh文件来传入正确的参数,主要包含如下字段:
--mymodel改为MyConvNeXt- 去掉多余的
--MyModel_Customized_param和--pre_trained_weights尤其是pretrained_path一般是在模型训练前初始化的。测试阶段无关。 - 将
--checkpoint_path设置为训练时输出所有checkpoint-xx.pth的文件夹。它会自动读取这下面所有的以.pth结尾的文件,并根据文件名中的数字确认该checkpoint来自于第几个epoch以正确的绘制测试时的指标折线图。 - 将
--test_data_json设置为前文含有多个测试集信息的JSON的路径。 - 其它参数按照显存等条件要求,酌情设置即可,
注意
如果你在训练时选择了--if_padding,这代表dataloader会将所有图像按照IML-ViT的0-padding方式组织,而非大多数模型的--if_resizing。那一定要确认测试时该参数与训练时保持一致,否则训练集和测试集不一致,一定会有性能损失。
可以通过Tensorboard可视化的图片双重检查是否正确选择padding或者resizing!
一个修改好的test_mymodel.sh如下:
base_dir="./eval_dir"
mkdir -p ${base_dir}
CUDA_VISIBLE_DEVICES=0,1 \
torchrun \
--standalone \
--nnodes=1 \
--nproc_per_node=2 \
./test.py \
--model MyConvNeXt \
--world_size 1 \
--test_data_json "./test_datasets.json" \
--checkpoint_path "./output_dir/" \
--test_batch_size 32 \
--image_size 512 \
--if_resizing \
--output_dir ${base_dir}/ \
--log_dir ${base_dir}/ \
2> ${base_dir}/error.log 1>${base_dir}/logs.log
然后,记得修改test.py开头的from mymodel import MyModel为from mymodel import MyConvNeXt。
此时,运行如下指令即可开始批量在各种测试集上测试指标:
sh test_mymodel.sh
此时也可以通过Tensorboard来查看测试进度和结果。可以在左侧的filter框过滤eval_dir来仅查看此次测试的输出结果。
tensorboard --logdir ./
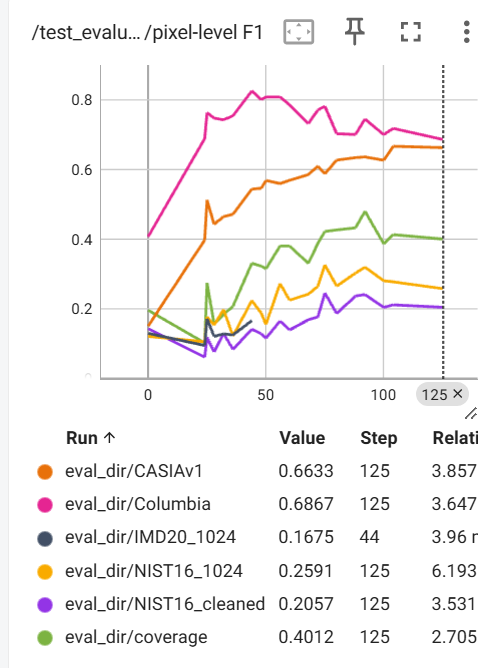
测试后得到的多个数据集的指标折线图如下,选择综合性能最好的Checkpoint,并在论文中记录相应的数据即可。
鲁棒性测试
鲁棒性测试因为对于“攻击类型”和“攻击强度”引入了两个维度进行网格搜索(gird search),所以一般只对测试阶段性能最好的那一个checkpoint进行鲁棒性测试。
所以相应的test_robust_mymodel.sh文件中,区别于test_mymodel.sh,这里的--checkpoint_path字段填入的路径指向一个具体的checkpoint,而非一个文件夹。
其他的字段同上,去掉无用的参数,填入需要的参数,并且记得修改test_robust.py开头的from mymodel import MyModel为from mymodel import MyConvNeXt。
我最终使用的test_robust_mymodel.sh如下
base_dir="./eval_robust_dir"
mkdir -p ${base_dir}
CUDA_VISIBLE_DEVICES=0,1 \
torchrun \
--standalone \
--nnodes=1 \
--nproc_per_node=2 \
./test_robust.py \
--model MyConvNeXt \
--world_size 1 \
--test_data_path "/mnt/data0/public_datasets/IML/CASIA1.0" \
--checkpoint_path "/mnt/data0/xiaochen/workspace/IMDLBenCo_pure/guide/benco/output_dir/checkpoint-92.pth" \
--test_batch_size 32 \
--image_size 512 \
--if_resizing \
--output_dir ${base_dir}/ \
--log_dir ${base_dir}/ \
2> ${base_dir}/error.log 1>${base_dir}/logs.log
鲁棒性测试具体的攻击策略和强度的调整需要修改test_robust.py,请通过搜索TODO来定位到这段可以修改的代码:
"""=================================================
Modify here to Set the robustness test parameters TODO
==================================================="""
robustness_list = [
GaussianBlurWrapper([0, 3, 7, 11, 15, 19, 23]),
GaussianNoiseWrapper([3, 7, 11, 15, 19, 23]),
JpegCompressionWrapper([50, 60, 70, 80, 90, 100])
]
这些wrapper后面的列表代表具体攻击的强度,他们内部封装了Albumentation提供的Transform来实现攻击。wrapper本身的实现请参考此链接。
特别的,你可以在当前路径下参考源码中wrapper的实现封装新的自定义wrapper,然后像from mymodel import MyConvNeXt一样import你自己的wrapper到这里使用。这样无需修改源码,也能实现自定义灵活的鲁棒性测试。
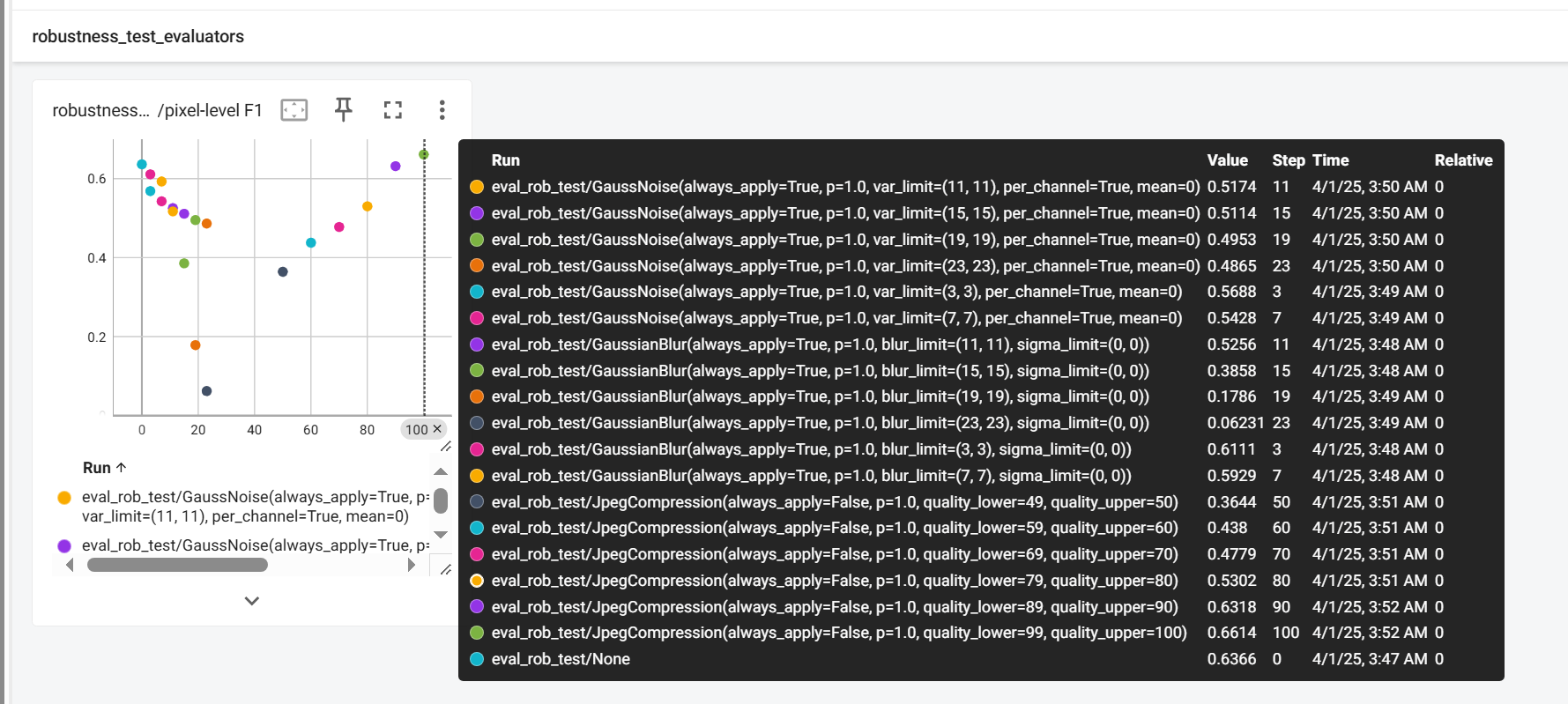
对于测试结果,同样的,你可以通过Tensorboard查看:
tensorboard --logdir ./
这时候可能会产生很多很多不同的记录,请活用Tensorboard左上角的filter功能,过滤你当前需要记录的攻击类型和响应的结果。
结语
这样我们就完成了一次从头到尾自己设计模型,训练模型,完成测试及鲁棒性测试的过程。有任何疑惑或者不完善的地方,欢迎向我们的仓库提issue或者给作者团队发邮件联系。第一手用户的建议对我们,以及对今后的学者帮助都会很大!